世界備份日遇上AI:資料只是備份,還是成為訓練素材?
2026年3月30日 13:22 李佳恩
3月31日是「世界備份日」(World Backup Day)。活動最早在 Reddit 上,由一群關心資料保存的使用者發起,刻意把日期訂在愚人節前一天,提醒人們別等到資料不見才後悔。到了AI時代,越來越多AI服務讀取照片、文件、對話紀錄,甚至整理生活資訊,資料一旦上傳雲端,資料是否成為訓練AI的素材?
雲端備份和AI服務取用資料是兩件事。以OpenAI目前公開說明為例,個人版 ChatGPT、Sora、Operator 內容,可能會被用來改善模型,但使用者可以到設定的資料控制中,關閉「為所有人改善模型」,或在新對話中開啟「臨時聊天」,如同開啟無痕模式,對話不會出現在歷史紀錄,也不會用來訓練模型。
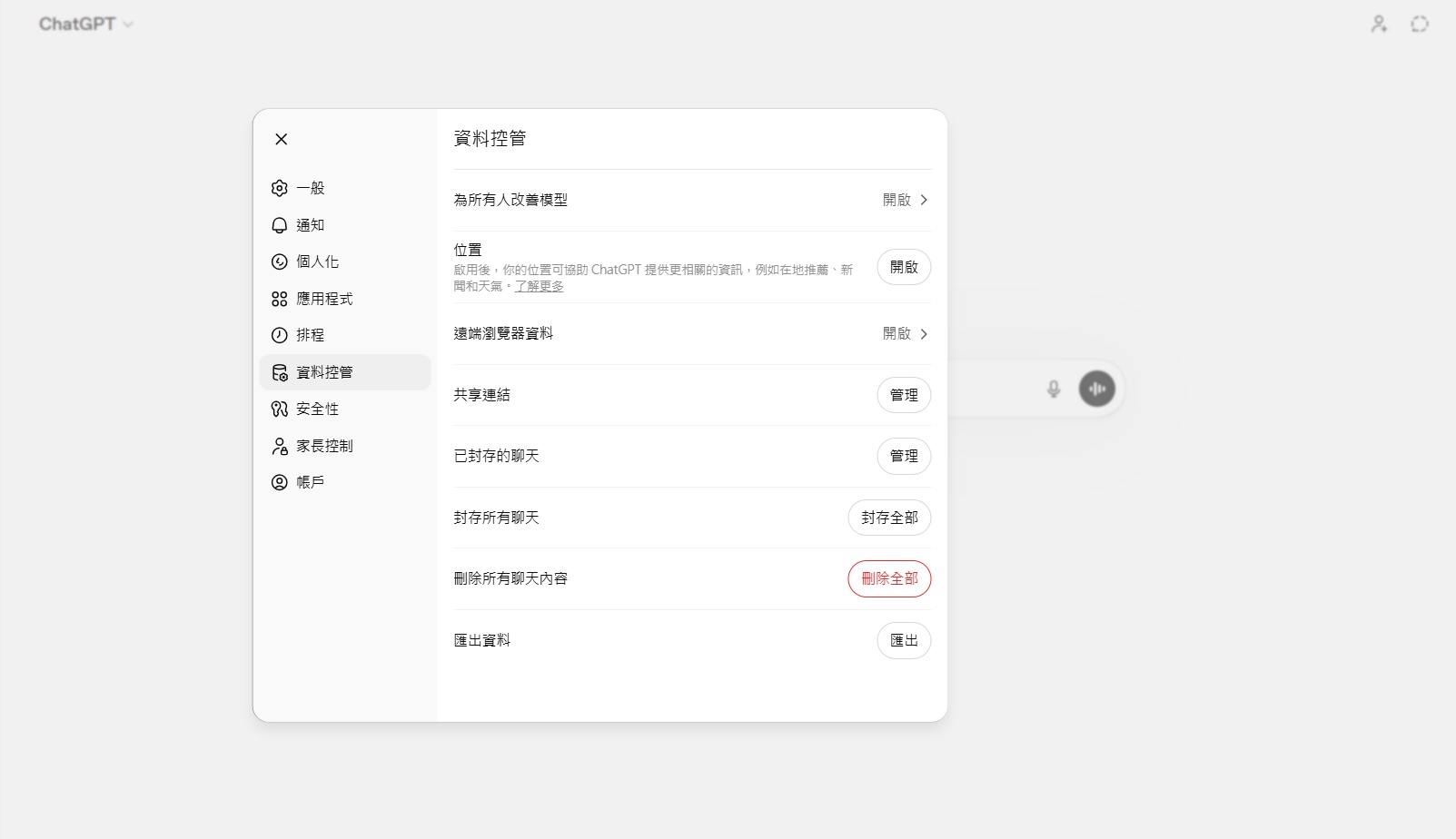 個人版需要設定,商務版如 ChatGPT Team、Enterprise 與 API,OpenAI則寫明預設不以客戶輸入與輸出作模型訓練。圖/翻攝自ChatGPT使用畫面
個人版需要設定,商務版如 ChatGPT Team、Enterprise 與 API,OpenAI則寫明預設不以客戶輸入與輸出作模型訓練。圖/翻攝自ChatGPT使用畫面
Google推出 Gemini 的個人化功能時強調,Gemini不會直接拿 Gmail 信箱或 Google 相簿內容來訓練模型,訓練主要來自使用者在 Gemini 裡的提示與模型回覆,並會盡量過濾或模糊化個資。
但Google同時說明,若將 Google 相簿連接到其他Google服務,其他服務系統可能會使用,從Google相簿整理出來的摘要、推論、生成內容,這些衍生資訊也可能被用來改進模型。換句話說,不一定是原始照片直接被拿去訓練,但照片經過摘要、推論、串接後,仍可能進入AI系統的處理流程。
平台常強調並非直接拿原始備份檔訓練,但從使用者角度看,只要資料被系統讀取、分析、轉成摘要或推論,再用於改善功能,界線就變得模糊。美國著作權局2025年發布的《Copyright and Artificial Intelligence》第三部分指出,最初下載與儲存受著作權保護作品、以及訓練過程中的中間重製,都可能碰到重製權問題。報告同時認為,把大量資料拿來訓練基礎模型「通常具有某種轉化性」,但是否構成合理使用,仍要看用途、作品性質、使用量,以及對原作品市場的影響,不能一概而論。
在AI時代,怎麼用才不踩雷?
台灣政府與專家提醒民眾:便利與風險同時存在。彰化縣衛生局直言,不是所有AI平台都會「保守秘密」,身分證字號、帳號密碼、健康資訊或家庭與工作細節,都有可能被系統記錄、分析,甚至在不同情境下被誤用。專家則普遍建議,應建立「最小揭露」的使用習慣,只提供完成任務所必要的資料,避免一次輸入過多真實資訊。
台灣科技媒體中心整理國立中山大學資訊工程學系助理教授徐瑞壕專家意見,使用AI時應掌握幾個核心原則:第一是避免輸入敏感資訊,包括個資、財務、醫療與公司機密;第二是選擇有清楚隱私政策的平台,並善用「不記錄對話」、「不作模型訓練」等設定;第三是保持查證與判斷能力,不要完全依賴AI的回答做重要決策。
在AI時代,備份不只是把資料存好,更是理解資料可能被如何使用、流向哪裡,以及自己是否保有控制權,是否能關掉,以及資料出現問題時,是否有通知和救濟機制。對一般使用者而言,真正需要建立,不只是備份習慣,而是新的數位自我保護意識。